Antlr4 项目
在开始入门前,需要知道Antlr项目的基础知识。Antlr4的Jar中由两个关键部分,一个是Antlr4工具,而另一个则是Antlr4运行库(运行时语法分析)API。通常来说,对一个语法运行Antlr4指的时通过Antlr4工具来生成一些代码,包括语法分析器和词法分析器。而一个Antlr4项目的一般流程是:
- 创建Antlr4语法文件
- 对其运行Antlr4工具,生成相关代码
- 与运行库一起编译相关代码
- 将编译后的代码与运行库一起运行
Antlr4的语法文件尾缀为
g4
Short转Unicode - 翻译器
开始第一个入门的项目,在这个项目里,需要实现一个工具,可以将Short数组转换为一个Unicode的字符串。例如将{99, 3, 451}转换为"\u0063\u0003\u01c3"。
编写语法文件
首先需要定义语法,在语法文件里我们可以这样指定:
grammar ArrayInit;
init : '{' value (',' value)* '}' ; // 至少有一个Value
value : init // value可以嵌套花括号
| INT // 也可以是一个整数
;
INT : [0-9]+ ; // 整数词法,它由一个或多个数字组成
WS : [ \t\r\n]+ -> skip ; // 丢弃空白符号相关解释在注释里都有,应该也很容易理解了。
运行Antlr4工具
执行antlr .\ArrayInit.g4,这会生成很多文件,如下图:
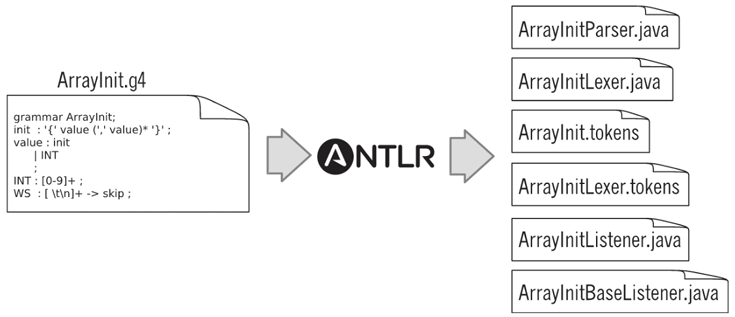
ArrayInitParser.java:包含一个语法分析器类的定义,专门用于识别我们的语法ArrayInitLexer.java:将输入字符序列分解成词汇符号ArrayInit.tokens:将定义的词法符号指定一个数字形式的类型,存储到此文件中ArrayInitListener.java、ArrayInitBaseListener.java:监听器模式下定义的接口与基类,我们只需要继承基类,覆盖掉需要实现的回调方法即可
测试语法分析器
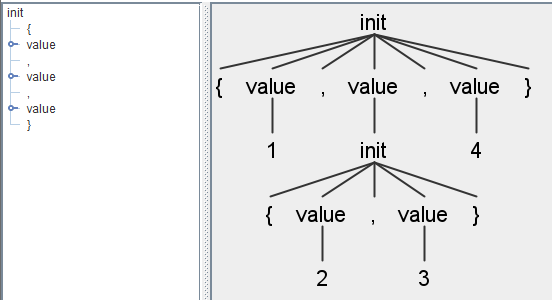
在开始编写处理的代码之前,先对语法分析器进行验证,执行命令:
echo "{1,{2,3},4}" | grun ArrayInit init -gui可以看到语法分析树符合了我们对语法的定义:
集成Java程序与语法分析器
接下来我们的Java程序从Stdin获取输入,然后使用LISP风格打印语法树,代码如下:
import org.antlr.v4.runtime.*;
class Test {
public static void main(String[] args) throws Exception {
CharStream stream = CharStreams.fromStream(System.in); // 从Stdin构建CharStream
ArrayInitLexer lexer = new ArrayInitLexer(stream); // 创建词法分析器
CommonTokenStream tokens = new CommonTokenStream(lexer); // 创建词法符号的缓冲区
ArrayInitParser parser = new ArrayInitParser(tokens); // 创建语法分析器,处理词法符号缓冲区中的内容
ArrayInitParser.InitContext tree = parser.init(); // 针对init规则,开始语法分析
System.out.println(tree.toStringTree());
}
}与运行库一起编译相关代码
随机编译相关代码:
cpantlr *.java将编译后的代码与运行库一起运行
执行查看解析树:
echo "{1, {2, 3}, 4}" | runantlr Test得到下列输出:
([] { ([5] 1) , ([7] ([15 7] { ([5 15 7] 2) , ([7 15 7] 3) })) , ([7] 4) })编写实际业务代码
上面实际为了演示操作流程,并未定义任何处理代码,接下来实现具体的业务代码。
在实际的业务中,就不考虑可能嵌套的括号了,对于{99, 3, 451}想要转换为"\u0063\u0003\u01c3",那么显然,只需要简单的映射一下就好了。
在前面的Antlr4 监听器提到,每个规则都有其对应的enter和exit方法;而这里的规则有两个,一个为init一个为value,在这里的调用顺序不难推导是enterInit=>enterValue=>exitValue=>exitInit,注意中间的enterValue和exitValue可能被调用多次。
那么显然的,我们只需要在enterInit输出",在enterValue时输出其short对应的Unicode码,在exitInit时输出",就成功的映射了,具体代码如下:
public class ShortToUnicodeString extends ArrayInitBaseListener{
@Override
public void enterInit(ArrayInitParser.InitContext ctx) {
System.out.print('"');
}
@Override
public void exitInit(ArrayInitParser.InitContext ctx) {
System.out.print('"');
}
@Override
public void enterValue(ArrayInitParser.ValueContext ctx) {
int value = Integer.valueOf(ctx.INT().getText());
System.out.printf("\\u%04x", value);
}
}接下来修改一下调用的类:
import org.antlr.v4.runtime.*;
import org.antlr.v4.runtime.tree.ParseTreeWalker;
class Test {
public static void main(String[] args) throws Exception {
CharStream stream = CharStreams.fromStream(System.in); // 从Stdin构建CharStream
ArrayInitLexer lexer = new ArrayInitLexer(stream); // 创建词法分析器
CommonTokenStream tokens = new CommonTokenStream(lexer); // 创建词法符号的缓冲区
ArrayInitParser parser = new ArrayInitParser(tokens); // 创建语法分析器,处理词法符号缓冲区中的内容
ArrayInitParser.InitContext tree = parser.init(); // 针对init规则,开始语法分析
ParseTreeWalker walker = new ParseTreeWalker();
walker.walk(new ShortToUnicodeString(), tree);
System.out.println();
}
}这样就完成了,测试一下:
echo "{99, 3, 451}" | runantlr Test
"\u0063\u0003\u01c3"表达式解析 - 解释器
从这里开始就不按照流程来编排文章了,流程一致,但是从这里开始重点在规则文件的书写以及功能的实现上。
语法规则
接下来通过Antlr4来实现一个表达式解析的程序;先假定我们可能有以下表达式:
193
a = 5
b = 6
a+b*2
(1+2)*3上述的每一行均为一个表达式,需要程序解析上述表达式并输出。那么表达式的定义可以是一个数字、一个赋值表达式、或者拥有运算符号的一串字符串。
接下来参考Antlr4 语法说明进行语法规则的编写;看上面的表达式,首先定义数字词法:
INT : [0-9]+ ;然后我们可以得到第一个语法:
expr : INT ;再看赋值表达式,显然它是由一个标识符(ID) + '=' + INT组成的,于是可以得到:
stat : ID '=' INT;但是这样就够了吗?并不是,赋值时可能右侧的还是一个表达式,因此可以把这里的INT换成expr,而expr本身又匹配了INT,因此这里就已经完成了赋值表达式的匹配(这里为了简单,标识符仅使用英文字母表示):
grammar Expr;
stat : ID '=' expr;
expr : INT ;
INT : [0-9]+ ;
ID : [a-zA-Z]+ ;接下来考虑一下运算符号,运算符号在之前的例子里也有提及,只需要修改一下expr语法即可:
grammar Expr;
stat : ID '=' expr;
expr : '(' expr ')'
| expr ('*'|'/') expr
| expr ('+'|'-') expr
| INT
;
INT : [0-9]+ ;
ID : [a-zA-Z]+ ;但是就到这了吗?显然不是,别忘了语句a+b*2,这表达式可不在我们的匹配里,因为我们的表达式现在的递归出口是INT,并没有ID,因此并不能匹配到它;此外,还需要将stat表达式修改为能匹配到上述所有的表达式;考虑到每行都是一个表达式,因此还可以匹配一下换行,最后的匹配规则如下:
grammar Expr;
prog: stat+ ; // 匹配若干行表达式
stat: expr NEWLINE // 单纯表达式与换行
| ID '=' expr NEWLINE // 赋值表达式与换行
| NEWLINE // 简单换行
;
expr: '(' expr ')' // 括号表达式,递归匹配
| expr ('*'|'/') expr // 乘除表达式,递归匹配
| expr ('+'|'-') expr // 加减表达式,递归匹配
| INT // 数字
| ID // 标识符
;
ID : [a-zA-Z]+ ;
INT : [0-9]+ ;
NEWLINE : '\r'? '\n' ;
WS : [ \t]+ -> skip ;现在来看一下语法规则的解析是否正确(将测试表达式写入t.expr中):
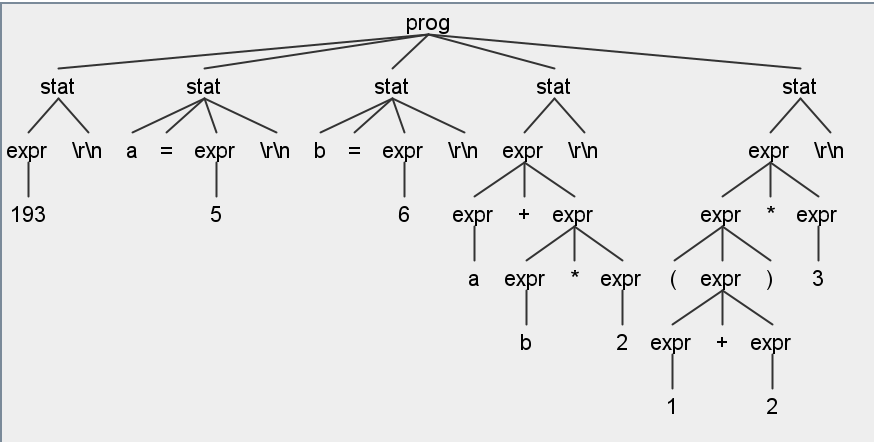
PS> cat .\t.expr | grun Expr prog -tree
(prog (stat (expr 193) \r\n) (stat a = (expr 5) \r\n) (stat b = (expr 6) \r\n) (stat (expr (expr a) + (expr (expr b) * (expr 2))) \r\n) (stat (expr (expr ( (expr (expr 1) + (expr 2)) )) * (expr 3)) \r\n)可以看到能够正确解析表达式,处理相关优先级;GUI如下:
拆分逻辑单元
尽管上面的语法文件定义很简短,但是我们迟早会将其写的异常庞大,因此,将其进行拆分成逻辑单元会更加简洁;一种不错的方案是将其拆分为词法和语法。
拆分出来的词法文件如下:
lexer grammar CommonLexerRules;
ID : [a-zA-Z]+ ;
INT : [0-9]+ ;
NEWLINE : '\r'? '\n' ;
WS : [ \t]+ -> skip ;注意是
lexer grammar,不是grammar
拆分出来的语法文件如下:
grammar LibExpr;
import CommonLexerRules;
prog: stat+ ; // 匹配若干行表达式
stat: expr NEWLINE // 单纯表达式与换行
| ID '=' expr NEWLINE // 赋值表达式与换行
| NEWLINE // 简单换行
;
expr: '(' expr ')' // 括号表达式,递归匹配
| expr ('*'|'/') expr // 乘除表达式,递归匹配
| expr ('+'|'-') expr // 加减表达式,递归匹配
| INT // 数字
| ID // 标识符
;注意需要
import词法
而构建则一样,只需要指定LibExpr进行构建即可,它会自动导入CommonLexerRules。
语法标签及词法命名
在上面的语法中,例如expr,有很多分支都可以匹配成expr,那么对于我们而言,如何确定当前是哪一个分支呢?最好的方案就是标签,Antlr4会根据标签生成不同的访问器方法,而为一个分支确定标签也十分简单,使用#即可;当可以确定一个分支时,还有一个问题,如何确定其中的词法字符呢?例如'*'|'/',应该如何得知当前是*还是/呢?我们自然可以通过获取字符串然后进行判断得知,但是更好的一种方法是,为这个词法字符取一个名字,然后去判断。那么将上面的语法规则修改后得到如下:
grammar LabeledExpr;
prog: stat+ ;
stat: expr NEWLINE # printExpr
| ID '=' expr NEWLINE # assign
| NEWLINE # blank
;
expr: expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| INT # int
| ID # id
| '(' expr ')' # parens
;
MUL : '*' ; // assigns token name to '*' used above in grammar
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;
ID : [a-zA-Z]+ ; // match identifiers
INT : [0-9]+ ; // match integers
NEWLINE:'\r'? '\n' ; // return newlines to parser (is end-statement signal)
WS : [ \t]+ -> skip ; // toss out whitespace
注意我们为语法的每一个分支都打了标签,对每一个|的词法都命名为op,同时为这类字符定义了词法名,方便进行判断。
访问器解析表达式
在定义好了语法规则后,就可以使用Antlr4以访问器模式生成相关的代码了:
antlr -no-listener -visitor LabeledExpr.g4然后我们实现一个EvalVisitor,继承于LabeledExprBaseVisitor<Integer>,注意,此处指定泛型Integer是因为我们的计算只涉及到整型数;前面说到Antlr4会生成对应标签的访问器方法,因此我们只需要覆盖对应的方法即可。
public class EvalVisitor extends LabeledExprBaseVisitor<Integer>{
@Override
public Integer visitAssign(LabeledExprParser.AssignContext ctx) {
}
@Override
public Integer visitPrintExpr(LabeledExprParser.PrintExprContext ctx) {
}
@Override
public Integer visitInt(LabeledExprParser.IntContext ctx) {
}
@Override
public Integer visitId(LabeledExprParser.IdContext ctx) {
}
@Override
public Integer visitMulDiv(LabeledExprParser.MulDivContext ctx) {
}
@Override
public Integer visitAddSub(LabeledExprParser.AddSubContext ctx) {
}
@Override
public Integer visitParens(LabeledExprParser.ParensContext ctx) {
}
}除了blank我们无需对其操作外,其它的都需要对其进行操作。
接下来先考虑赋值,显然需要在内存中对其进行存储,这里可以使用HashMap完成,如下:
Map<String, Integer> memory = new HashMap<String, Integer>();
@Override
public Integer visitAssign(LabeledExprParser.AssignContext ctx) {
String id = ctx.ID().getText();
int value = visit(ctx.expr());
memory.put(id, value);
return value;
}这里对代码略微进行一下解释,ctx.ID().getText()非常简单,就是获取ID词法匹配的字符串,而expr注意是一个语法,这里使用visit主动去解析这个表达式,它会返回对应解析的值(这取决于Visitor是否已经实现了解析,这里假定我们的Visitor已经实现了解析功能)。
再考虑乘除法,同样的,获取左右两个expr,然后通过visit获取其解析值,再进行乘除即可:
@Override
public Integer visitMulDiv(LabeledExprParser.MulDivContext ctx) {
int left = visit(ctx.expr(0));
int right = visit(ctx.expr(1));
if (ctx.op.getType() == LabeledExprParser.MUL) return left * right;
else return left / right;
}这里也需要稍微解释一下,ctx.expr()如果在语法里只要一个expr那么自然就返回了对应的那个expr,但是如果是多个,则需要传入索引值,获取对应的Context;随后通过命名的op词法获取其对应类型,然后做出对应的乘除法。
依照这样的思路,最后再实现递归的出口INT以及ID即可,最后的完整代码如下:
import java.util.HashMap;
import java.util.Map;
public class EvalVisitor extends LabeledExprBaseVisitor<Integer>{
Map<String, Integer> memory = new HashMap<String, Integer>();
@Override
public Integer visitAssign(LabeledExprParser.AssignContext ctx) {
String id = ctx.ID().getText();
int value = visit(ctx.expr());
memory.put(id, value);
return value;
}
@Override
public Integer visitPrintExpr(LabeledExprParser.PrintExprContext ctx) {
Integer value = visit(ctx.expr());
System.out.println(value);
return 0;
}
@Override
public Integer visitInt(LabeledExprParser.IntContext ctx) {
return Integer.valueOf(ctx.INT().getText());
}
@Override
public Integer visitId(LabeledExprParser.IdContext ctx) {
String id = ctx.ID().getText();
if (memory.containsKey(id)) return memory.get(id);
return 0;
}
@Override
public Integer visitMulDiv(LabeledExprParser.MulDivContext ctx) {
int left = visit(ctx.expr(0));
int right = visit(ctx.expr(1));
if (ctx.op.getType() == LabeledExprParser.MUL) return left * right;
else return left / right;
}
@Override
public Integer visitAddSub(LabeledExprParser.AddSubContext ctx) {
int left = visit(ctx.expr(0));
int right = visit(ctx.expr(1));
if (ctx.op.getType() == LabeledExprParser.ADD) return left + right;
else return left - right;
}
@Override
public Integer visitParens(LabeledExprParser.ParensContext ctx) {
return visit(ctx.expr());
}
}
然后实现我们的程序入口:
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTree;
public class Calc {
public static void main(String[] args) throws Exception{
String inputFile = null;
if (args.length > 0) inputFile = args[0];
CharStream stream = CharStreams.fromFileName(inputFile);
LabeledExprLexer lexer = new LabeledExprLexer(stream);
CommonTokenStream tokens = new CommonTokenStream(lexer);
LabeledExprParser parser = new LabeledExprParser(tokens);
ParseTree tree = parser.prog();
EvalVisitor eval = new EvalVisitor();
eval.visit(tree);
}
}
编译后执行:
runantlr Calc .\t.expr
193
17
9可以看到没有问题。
增加函数支持
接下来考虑两个新功能,一个是clear,用于清除当前的内存,即所有变量都清零;另一个是实现函数,例如sin、cos一类的三角函数。
对于clear而言,很简单,只需要在上面的规则增加stat一个分支即可匹配:
stat: expr NEWLINE # printExpr
| ID '=' expr NEWLINE # assign
| NEWLINE # blank
| 'clear' NEWLINE # clear
;那么对于函数呢?函数显然也可以作为表达式的一种,因此可以expr中创建分支,那么对于函数的匹配可以写成ID '(' expr '),于是得到最终的语法规则:
expr: expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| INT # int
| ID # id
| '(' expr ')' # parens
| ID '(' expr ')' # function
;这里
expr虽然能匹配成( expr ),但是不能写成ID expr,因为每次匹配不一定就是匹配到该规则;所以为了避免歧义,应该写成上面的形式。
那么接下来考虑实现,对于clear显然并没有什么特殊的,只需要将HashMap清空即可:
@Override
public Integer visitClear(LabeledExprParser.ClearContext ctx) {
memory.clear();
return 0;
}而对于函数支持,考虑到返回值可能是浮点数,因此这里开始全部以浮点数计算;即把所有的int替换为double,所有的Integer替换为Double;计算也很简单,代码如下:
interface Function {
double calc(double value);
}
Map<String, Function> functionMap = new HashMap<String, Function>();
public void registerFunction(String name, Function func) {
this.functionMap.put(name, func);
}
@Override
public Double visitFunction(LabeledExprParser.FunctionContext ctx) {
double value = visit(ctx.expr());
String functionName = ctx.ID().getText();
if (functionMap.containsKey(functionName)) {
return functionMap.get(functionName).calc(value);
}
return 0.0;
}完整的代码如下:
import java.util.HashMap;
import java.util.Map;
public class EvalVisitor extends LabeledExprBaseVisitor<Double>{
interface Function {
double calc(double value);
}
Map<String, Function> functionMap = new HashMap<String, Function>();
Map<String, Double> memory = new HashMap<String, Double>();
public void registerFunction(String name, Function func) {
this.functionMap.put(name, func);
}
@Override
public Double visitAssign(LabeledExprParser.AssignContext ctx) {
String id = ctx.ID().getText();
double value = visit(ctx.expr());
memory.put(id, value);
return value;
}
@Override
public Double visitPrintExpr(LabeledExprParser.PrintExprContext ctx) {
Double value = visit(ctx.expr());
System.out.println(value);
return 0.0;
}
@Override
public Double visitInt(LabeledExprParser.IntContext ctx) {
return Double.valueOf(ctx.INT().getText());
}
@Override
public Double visitId(LabeledExprParser.IdContext ctx) {
String id = ctx.ID().getText();
if (memory.containsKey(id)) return memory.get(id);
return 0.0;
}
@Override
public Double visitMulDiv(LabeledExprParser.MulDivContext ctx) {
double left = visit(ctx.expr(0));
double right = visit(ctx.expr(1));
if (ctx.op.getType() == LabeledExprParser.MUL) return left * right;
else return left / right;
}
@Override
public Double visitAddSub(LabeledExprParser.AddSubContext ctx) {
double left = visit(ctx.expr(0));
double right = visit(ctx.expr(1));
if (ctx.op.getType() == LabeledExprParser.ADD) return left + right;
else return left - right;
}
@Override
public Double visitFunction(LabeledExprParser.FunctionContext ctx) {
double value = visit(ctx.expr());
String functionName = ctx.ID().getText();
if (functionMap.containsKey(functionName)) {
return functionMap.get(functionName).calc(value);
}
return 0.0;
}
@Override
public Double visitParens(LabeledExprParser.ParensContext ctx) {
return visit(ctx.expr());
}
@Override
public Double visitClear(LabeledExprParser.ClearContext ctx) {
memory.clear();
return 0.0;
}
}接下来改程序,为其添加两个函数支持:
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTree;
public class Calc {
public static void main(String[] args) throws Exception{
String inputFile = null;
if (args.length > 0) inputFile = args[0];
CharStream stream = CharStreams.fromFileName(inputFile);
LabeledExprLexer lexer = new LabeledExprLexer(stream);
CommonTokenStream tokens = new CommonTokenStream(lexer);
LabeledExprParser parser = new LabeledExprParser(tokens);
ParseTree tree = parser.prog();
EvalVisitor eval = new EvalVisitor();
eval.registerFunction("sin", v -> Math.sin(v));
eval.registerFunction("cos", v -> Math.cos(v));
eval.visit(tree);
}
}将表达式更改为:
193
a = 5
b = 6
a+b*2
(1+2)*3
cos(a)
clear
a
b
sin((1+2)*3)执行查看输出:
➜ runantlr.bat Calc .\t.expr
193.0
17.0
9.0
0.28366218546322625
0.0
0.0
0.4121184852417566可以发现准确无误。
Java接口提取 - 翻译器
现在考虑一个程序,将一份Java代码中的所有方法提取出来,并且生成Java接口文件,对于类Test,生成ITest接口。对于Java语言而言,我们无需自己去编写规则,在仓库GitHub - antlr/grammars-v4: Grammars written for ANTLR v4; expectation that the grammars are free of actions.里存有大量编程语言的语法规则,这里使用java/java内的语法规则。
在这里面的规则可以看到导入使用了
options {tokenVocab = JavaLexer;},import和C语言的#include类似,而tokenVocab则需要先编译词法分析器,更好一些。
在这里面我们暂时只需要两个定义:
classDeclaration
: CLASS identifier typeParameters? (EXTENDS typeType)? (IMPLEMENTS typeList)? (
PERMITS typeList
)? // Java17
classBody
;
methodDeclaration
: typeTypeOrVoid identifier formalParameters ('[' ']')* (THROWS qualifiedNameList)? methodBody
;我们先使用Antlr4生成对应的代码,注意由于使用了tokenVocab,我们需要先生成Lexer,再生成Parser:
antlr.bat .\JavaLexer.g4 && antlr.bat .\JavaParser.g4具体业务代码
在生成相关代码后,就要考虑一下实现了;显然,我们可以通过enterClassDeclaration和exitClassDeclaration的方法里输出接口定义;然后在enterMethodDeclaration里输出方法定义;开始前先通过GUI看看语法树的解析:
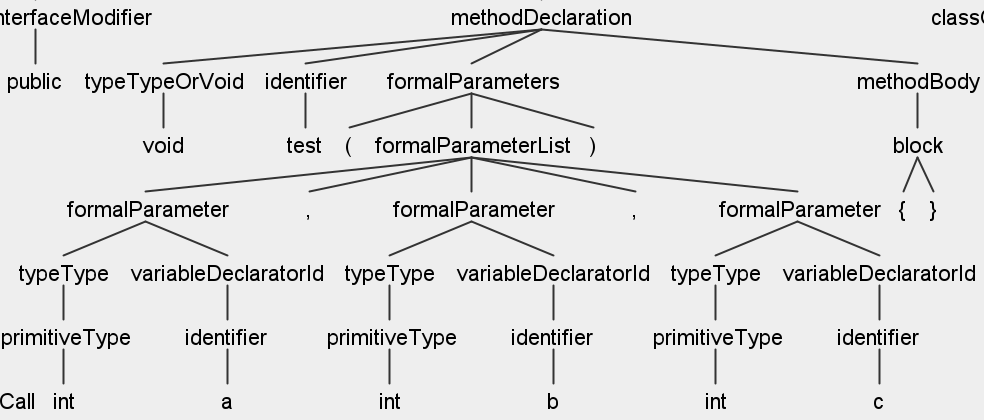
这是一个签名为void test(int a, int b, int c)的方法,那么语法树解析后是这样的;那么我们从MethodDeclarationContext中拿到的formalParameters实际上还需要再进入其formalParameterList,然后再通过索引获取到所有的formalParameter才行,具体如下:
@Override
public void enterMethodDeclaration(JavaParser.MethodDeclarationContext ctx) {
JavaParser.FormalParameterListContext formalParameterListContext = ctx.formalParameters().formalParameterList();
JavaParser.FormalParameterContext formalParameterContext = null;
int i = 0;
while(true) {
formalParameterContext = formalParameterListContext.formalParameter(i++);
if (formalParameterContext == null) break;
// do something
}
}那么这样就不难实现这个功能了:
public class ExtractInterfaceListener extends JavaParserBaseListener{
@Override
public void enterClassDeclaration(JavaParser.ClassDeclarationContext ctx) {
System.out.println("interface I" + ctx.identifier().getText() + " {");
}
@Override
public void exitClassDeclaration(JavaParser.ClassDeclarationContext ctx) {
System.out.println("}");
}
@Override
public void enterMethodDeclaration(JavaParser.MethodDeclarationContext ctx) {
JavaParser.FormalParameterListContext formalParameterListContext = ctx.formalParameters().formalParameterList();
if (formalParameterListContext == null) {
System.out.println("\t" + ctx.typeTypeOrVoid().getText() + " " + ctx.identifier().getText() + "();");
return;
}
String args = "";
JavaParser.FormalParameterContext formalParameterContext = null;
int i = 0;
while(true) {
formalParameterContext = formalParameterListContext.formalParameter(i++);
if (formalParameterContext == null) break;
args += ", " + formalParameterContext.typeType().getText() + " " + formalParameterContext.variableDeclaratorId().identifier().getText();
}
System.out.println("\t" + ctx.typeTypeOrVoid().getText() + " " + ctx.identifier().getText() + " " + "(" + args.substring(2) + ")" + ";");
}
}程序类:
import java.io.FileInputStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTree;
import org.antlr.v4.runtime.tree.ParseTreeWalker;
public class ExtractInterfaceTool {
public static void main(String[] args) throws Exception {
JavaLexer lexer = new JavaLexer(CharStreams.fromStream(new FileInputStream(args[0])));
CommonTokenStream tokens = new CommonTokenStream(lexer);
JavaParser parser = new JavaParser(tokens);
ParseTree tree = parser.compilationUnit();
ParseTreeWalker walker = new ParseTreeWalker();
ExtractInterfaceListener extractInterfaceListener = new ExtractInterfaceListener();
walker.walk(extractInterfaceListener, tree);
}
}测试一下:
➜ runantlr.bat ExtractInterfaceTool '.\ExtractInterfaceListener.java'
interface IExtractInterfaceListener {
void enterClassDeclaration(JavaParser.ClassDeclarationContext ctx);
void exitClassDeclaration(JavaParser.ClassDeclarationContext ctx);
void enterMethodDeclaration(JavaParser.MethodDeclarationContext ctx);
}但是上面的程序其实并不完善,如果在一个类中有内部类的话,那么就会出现异常了。
解决内部类问题
先通过GUI来看一下存在内部类时的场景:
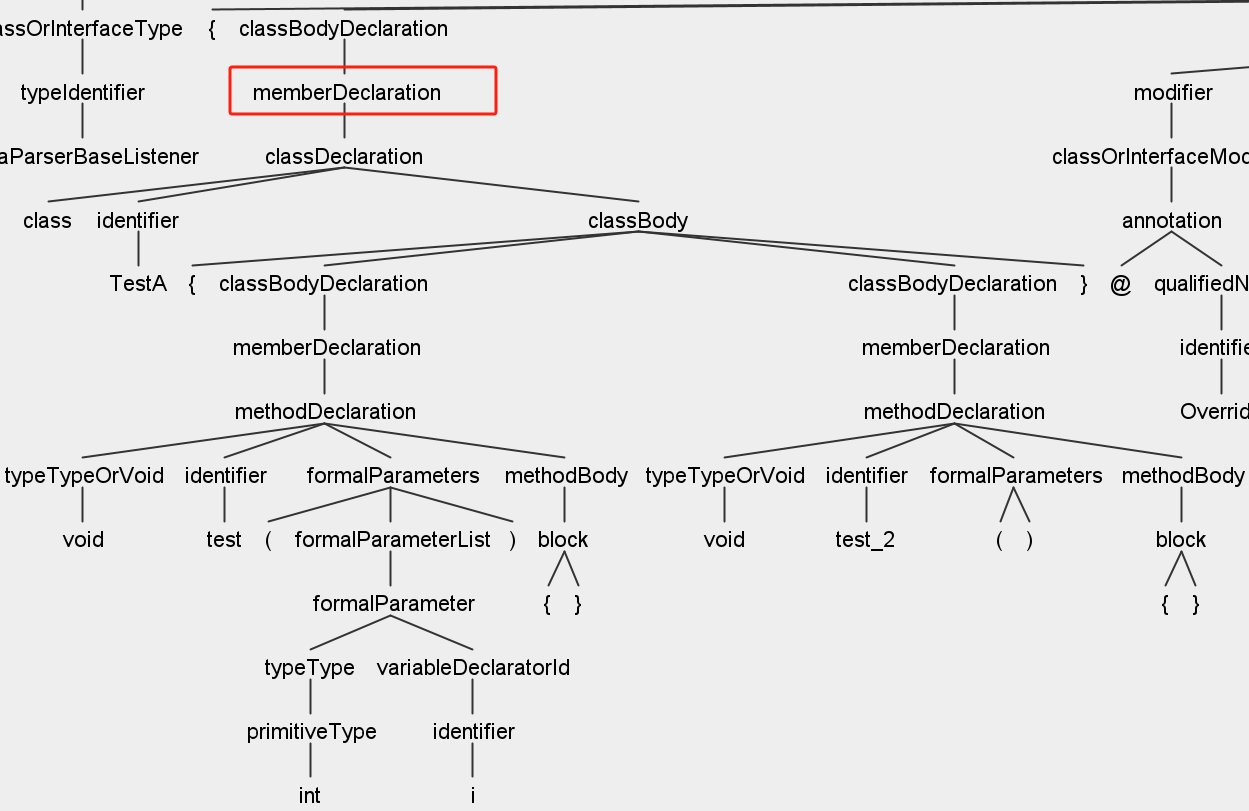
从图中不难看出内部类的parent实际是memberDeclaration,而一个常规类:

可以看出是typeDeclaration,那么我们就可以通过此方法来判断当前类是否为内部类了:
private boolean isInternalClass(RuleContext ctx) {
RuleContext p = ctx;
while (p != null) {
if (p instanceof JavaParser.ClassDeclarationContext && p.parent != null && p.parent instanceof JavaParser.MemberDeclarationContext) {
return true;
}
p = p.parent;
}
return false;
}这里不断向上取parant,是因为还可以应用到methodDeclaration的场景中,这样可以判断method是否为内部类方法;那么接下来就很简单了:
import org.antlr.v4.runtime.RuleContext;
public class ExtractInterfaceListener extends JavaParserBaseListener{
@Override
public void enterClassDeclaration(JavaParser.ClassDeclarationContext ctx) {
if (!isInternalClass(ctx))
System.out.println("interface I" + ctx.identifier().getText() + " {");
}
@Override
public void exitClassDeclaration(JavaParser.ClassDeclarationContext ctx) {
if (!isInternalClass(ctx))
System.out.println("}");
}
private boolean isInternalClass(RuleContext ctx) {
RuleContext p = ctx;
while (p != null) {
if (p instanceof JavaParser.ClassDeclarationContext && p.parent != null && p.parent instanceof JavaParser.MemberDeclarationContext) {
return true;
}
p = p.parent;
}
return false;
}
@Override
public void enterMethodDeclaration(JavaParser.MethodDeclarationContext ctx) {
if (isInternalClass(ctx)) return;
JavaParser.FormalParameterListContext formalParameterListContext = ctx.formalParameters().formalParameterList();
if (formalParameterListContext == null) {
System.out.println("\t" + ctx.typeTypeOrVoid().getText() + " " + ctx.identifier().getText() + "();");
return ;
}
String args = "";
JavaParser.FormalParameterContext formalParameterContext = null;
int i = 0;
while(true) {
formalParameterContext = formalParameterListContext.formalParameter(i++);
if (formalParameterContext == null) break;
args += ", " + formalParameterContext.typeType().getText() + " " + formalParameterContext.variableDeclaratorId().identifier().getText();
}
System.out.println("\t" + ctx.typeTypeOrVoid().getText() + " " + ctx.identifier().getText() + "(" + args.substring(2) + ")" + ";");
}
}增加import
在上面的代码中其实还有一点问题,即,没有把import一起导入,这个问题解决起来就十分简单了:
@Override
public void enterImportDeclaration(JavaParser.ImportDeclarationContext ctx) {
System.out.print("import ");
int i = 1;
if (ctx.STATIC() != null) {
i = 2;
System.out.print("static ");
}
for (; i < ctx.getChildCount(); i++) {
System.out.print(ctx.getChild(i).getText());
}
System.out.println();
}简化操作
让我们尝试把上面的操作简化一下。实际上在前面我们已经提及过,TokenStream是词法符号的缓冲区,因此我们可以直接从该缓冲区中获取到相关的词法内容,例如上面的import,实际上可以通过parser.getTokenStream().getText(ctx)来获取。对于参数表也是同样的:
public class ExtractInterfaceListener extends JavaParserBaseListener{
JavaParser parser;
public ExtractInterfaceListener(JavaParser parser) {
this.parser = parser;
}
@Override
public void enterClassDeclaration(JavaParser.ClassDeclarationContext ctx) {
if (!isInternalClass(ctx))
System.out.println("interface I" + ctx.identifier().getText() + " {");
}
@Override
public void exitClassDeclaration(JavaParser.ClassDeclarationContext ctx) {
if (!isInternalClass(ctx))
System.out.println("}");
}
private boolean isInternalClass(RuleContext ctx) {
RuleContext p = ctx;
while (p != null) {
if (p instanceof JavaParser.ClassDeclarationContext && p.parent != null && p.parent instanceof JavaParser.MemberDeclarationContext) {
return true;
}
p = p.parent;
}
return false;
}
@Override
public void enterMethodDeclaration(JavaParser.MethodDeclarationContext ctx) {
if (isInternalClass(ctx)) return;
System.out.println("\t" + ctx.typeTypeOrVoid().getText() + " " + ctx.identifier().getText() + parser.getTokenStream().getText(ctx.formalParameters()) + ";");
}
@Override
public void enterImportDeclaration(JavaParser.ImportDeclarationContext ctx) {
System.out.println(parser.getTokenStream().getText(ctx));
}
}