安装
通过Brew安装二进制的程序即可,然后需要有一个SDK,克隆此仓库到自己的用户目录下:Github/CodeQL
或者直接克隆starter仓库:GitHub - github/vscode-codeql-starter: Starter workspace to use with the CodeQL extension for Visual Studio Code.:
git clone --recursive https://github.com/github/vscode-codeql-starter一定要加
--recursive,因为这个参考也包含了上面所说的SDK。
然后VSCode安装CodeQL插件;到这里就安装完了。
创建数据库
通过:
codeql database create ./ql-database --language=python --source-root=.即可创建,对于编译型语言,可能需要编译,例如Java:
codeql database create ./ql-database --language=java --command="/Users/evalexp/.soft/zulu8.86.0.25-ca-fx-jdk8.0.452-macosx_aarch64/bin/java -Dmaven.multiModuleProjectDirectory=/Users/evalexp/src/audit/jndi_test -Djansi.passthrough=true \"-Dmaven.home=/Applications/IntelliJ IDEA.app/Contents/plugins/maven/lib/maven3\" \"-Dclassworlds.conf=/Applications/IntelliJ IDEA.app/Contents/plugins/maven/lib/maven3/bin/m2.conf\" \"-Dmaven.ext.class.path=/Applications/IntelliJ IDEA.app/Contents/plugins/maven/lib/maven-event-listener.jar\" \"-javaagent:/Applications/IntelliJ IDEA.app/Contents/lib/idea_rt.jar=50163\" -Dfile.encoding=UTF-8 -classpath \"/Applications/IntelliJ IDEA.app/Contents/plugins/maven/lib/maven3/boot/plexus-classworlds.license:/Applications/IntelliJ IDEA.app/Contents/plugins/maven/lib/maven3/boot/plexus-classworlds-2.8.0.jar\" org.codehaus.classworlds.Launcher -Didea.version=2025.1.1.1 package -DskipTests" --source-root=.语法
先跟着官方的教程;参考:Writing CodeQL queries — CodeQL
基础查询结构
查询文件以.ql文件拓展名书写,且包含一个select,一个基础的查询结构如下:
/**
*
* Query metadata
*
*/
import /* ... CodeQL libraries or modules ... */
/* ... Optional, define CodeQL classes and predicates ... */
from /* ... variable declarations ... */
where /* ... logical formula ... */
select /* ... expressions ... */通过import可以导入库或者模块,上面的SDK已经包含了常规的支持语言的CodeQL库了。
通过from来声明你要在查询中使用的变量,每个声明必须是类型或者变量名,如果需要自定义类型,则需要使用classes进行定义,需要使用QL语言。
通过where子句来定义应用于from子句中可生成成果的逻辑条件,读起来有点绕,其实就是筛选from子句获取的数据,和sql的select * from a where 1=1的where差不多。
通过select来指定显示哪些东西;警示查询的select除了元素外,还应该包含一个字符串来表明为什么提出警示:
select element, string和常规Sql差不多,from其实就是作笛卡尔积,通过where来限制条件。
元数据
元数据提供了查询的重要信息,所有的查询都有以下的元数据属性:
| 属性 | 值 | 描述 |
|---|---|---|
| @description | <text> | 描述查询目的,以及为什么结果有用或重要。纯文本编写,使用单引号包裹代码部分 |
| @id | <text> | 用小写字母或者数字组成的序列,用/或-分割,必须唯一,用于识别查询。 |
| @previous-id | <text | 表示查询结果之前在其他查询上报告过,为其他查询的id。 |
| @kind | problempath-problem | 识别查询是警报还是路径 |
| @name | <text> | 定义查询标签的语句,使用纯文本编写,使用单引号包裹代码部分 |
| @tags | correctnessmaintainabilityreadabilitysecurity | 便于搜索的标签 |
| @precision | lowmediumhighvery-high | 可能性 |
| @problem.severity | errorwarningrecommendation | 问题严重程度,与@precision一起使用 |
| @security-severity | <score> | 安全等级,从0.0到10.0,与@tags security一起使用 |
查询帮助文档
编写此类文档主要提供查询相关的目的和使用的详细信息,其结构如下:
<!DOCTYPE qhelp SYSTEM "qhelp.dtd">
<qhelp>
CONTAINS one or more section-level elements
</qhelp>必须以qhelp作为根。
该文档的书写并不重要,参考文档即可:Query help files — CodeQL
定义查询的结果
绝大多数的查询中,都必须包含至少两列,即元素和字符串。
举个例子,假如需要查询代码中FastJSON的解析点,首先FastJSON解析时一般使用JSON.parseObject或者JSON.parse[XXX]这种形式;然后确定自己要获取的信息,这里我需要获取类名、方法名,调用的具体行号。
那么我这里只需要选择一个类型,即MethodCall,然后组合上面的条件即可,示例如下:
import java
from MethodCall mc
where
mc.getMethod().getName().regexpMatch("parse.*") and
mc.getMethod().getDeclaringType().getQualifiedName() = "com.alibaba.fastjson.JSON" and
mc.getCaller().getDeclaringType().getQualifiedName().regexpMatch("com\\.l4yn3\\.microserviceseclab.*")
select mc.getCaller().getDeclaringType().getName(), mc.getCaller(), mc.getLocation().getStartLine(), "FastJSON Parse Entry"这里的MethodCall是被调用的对象,首先我们匹配parse[XXX]的方法名,然后再限定被调用的类一定是com.alibaba.fastjson.JSON,最后限定调用者的位置在com.l4yn3.microservicesseclab的包中;如图,查找得非常流畅:
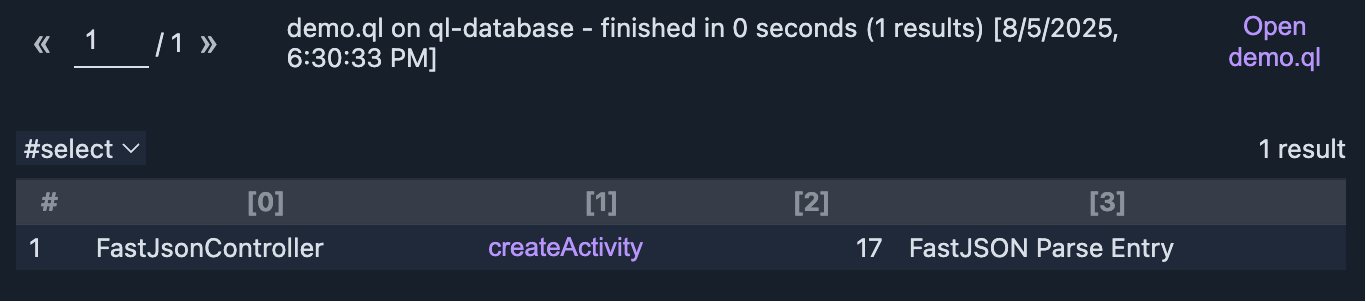
上面显示在代码的FastJsonController的createActivity方法中,也就是源码的17行,出现了FastJSON的parse调用:
在查询中提供位置
这一章节在官方的教程中叫做Providing locations in CodeQL queries,事实上这里可以加载外部数据作为映射,也可以直接提供位置。
URL
提供URL,可以自行定义一个类:
class JiraIssue extends ExternalData {
JiraIssue() {
getDataPath() = "JiraIssues.csv"
}
string getKey() {
result = getField(0)
}
string getURL() {
result = "http://mycompany.com/jira/" + getKey()
}
}文件
如果在vscode的拓展中,还可以提供一个文件位置,通过file协议来指向一个文件;在文件位置后跟4个整型数用于表示链接范围,例如file://opt/src/my/file.java:0:0:0:0表示整个文件;而file:///opt/src/my/file.java:1:1:2:1表示该文件的第一行第一列到第二行第一列;表示某一行可以这样file:///opt/src/my/file.java:1:0:1:0。
所有的索引都从1开始,0表示全部;所以0:0:0:0表示整体文件;1:0:1:0表示第一行。
文件夹
也可以像文件一样表示,使用folder协议,注意该协议不能通过尾号指定信息。
相对文件
通过使用relative协议实现,从默认数据库的源位置寻址。
数据流分析
相当重要的一个概率,譬如污点分析就可以通过此实现。
Java
本地数据流
本地数据流是指在单个方法或者单个可调用中的数据流;这比全局数据流更快、更简单、更精确。
使用本地数据流只需要导入:
import semmle.code.java.dataflow.DataFlow在DataFlow模块中,定义了类Node,表示数据可以流过的任何元素;Node分为表达式节点ExprNode和参数节点ParameterNode。通过Node的asExpr和asParameter在数据流节点和表达式或参数之间进行映射关系的转换:
class Node {
/** Gets the expression corresponding to this node, if any. */
Expr asExpr() { ... }
/** Gets the parameter corresponding to this node, if any. */
Parameter asParameter() { ... }
...
}如果希望转换为ExprNode或者ParameterNode,则直接调用exprNode或parameterNode将其进行转换即可:
/**
* Gets the node corresponding to expression `e`.
*/
ExprNode exprNode(Expr e) { ... }
/**
* Gets the node corresponding to the value of parameter `p` at function entry.
*/
ParameterNode parameterNode(Parameter p) { ... }方法localFlowStep(Node nodeFrom, Node nodeTo)表示是否直接的数据流从from到to节点。可以通过使用+或者*的操作符来对其应用为递归,或者使用预定义的方法localFlow,相当于localFlowStep*。
举个例子,从参数source到表达式sink,存在一条可通的数据流,可以这样写:
DataFlow::localFlow(DataFlow::parameterNode(source), DataFlow::exprNode(sink))本地污点分析
如果一个变量x是污点,那么对于代码:
String y = "hello " + x;显然y也将成为污点,因为x已经扩散到了y里。
污点追踪导入下面:
import semmle.code.java.dataflow.TaintTracking和本地数据流类似的,可以通过localTainStep(DataFlow::Node nodeFrom, DataFlow::Node nodeTo)以及localTain来跟踪污点。
样例 - 找出所有FileReader构造方法打开文件的文件名
首先很容易想到这个需求可以这么实现:
import java
from Constructor fileReader, Call call
where
fileReader.getDeclaringType().hasQualifiedName("java.io", "FileReader") and
call.getCallee() = fileReader
select call.getArgument(0)不过这样做有个问题,即无法追踪来源,它只能获取到构造参数,而非可以传递的值,那么使用本地流:
import java
import semmle.code.java.dataflow.DataFlow
from Constructor fileReader, Call call, Expr src
where
fileReader.getDeclaringType().hasQualifiedName("java.io", "FileReader") and
call.getCallee() = fileReader and
DataFlow::localFlow(DataFlow::exprNode(src), DataFlow::exprNode(call.getArgument(0)))
select src在这里新加了localFlow,表明从任意一个表达式到参数,这样就可以将传递的实际表达式获取,一般为常量或方法调用。
如果要查看从方法的参数到实际的FileReader构造,只需要将输入的改为参数即可:
import java
import semmle.code.java.dataflow.DataFlow
from Constructor fileReader, Call call, Parameter p
where
fileReader.getDeclaringType().hasQualifiedName("java.io", "FileReader") and
call.getCallee() = fileReader and
DataFlow::localFlow(DataFlow::parameterNode(p), DataFlow::exprNode(call.getArgument(0)))
select p样例 - 找出所有的格式化字符串非硬编码调用
即在格式化字符串时,格式串应该保证硬编码,否则可能出现安全问题。
整理思路:
- StringFormatMethod被调用
- 表达式为格式化串
- 表达式必须硬编码来自任何字符串面量
如下:
import java
import semmle.code.java.dataflow.DataFlow
import semmle.code.java.StringFormat
from StringFormatMethod format, MethodCall call, Expr formatString
where
call.getMethod() = format and // 调用format
call.getArgument(format.getFormatStringIndex()) = formatString and // 格式串匹配
not exists(DataFlow::Node source, DataFlow::Node sink |
DataFlow::localFlow(source, sink) and
source.asExpr() instanceof StringLiteral and
sink.asExpr() = formatString
) // 不存在从任意字符串量到格式串的流
select call, "Argument to String format method isn't hard-coded."样例 - 找出本地所有java.net.URL硬编码
import java
import semmle.code.java.dataflow.DataFlow
from Constructor url, Call call, StringLiteral src
where
call.getCallee() = url and
url.getDeclaringType().hsQualifiedName("java.net", "URL") and
DataFlow::localFlow(DataFlow::exprNode(src), DataFlow::exprNode(call.getArgument(0)))也就是硬编码的字符串面量流向参数;这样就可以将其所有硬编码的URL对象筛选出来了。
全局数据流
全局数据流跟踪整个程序流程,自然这更加强大,不过也需要更多的分析时间与内存去响应。
注意可以创建一个路径查询对数据流的路径进行建模,在VS Code插件中查看时需确保有正确的元数据以及select 子句。
使用全局数据流稍微有点不一样,与本地数据流很有大区别,本地数据流通过DataFlow::localFlow来进行调用,但是全局数据流需要定义一个配置来进行分析:
import java
import semmle.code.java.dataflow.DataFlow
module MyFlowConfiguration implements DataFlow::ConfigSig {
predicate isSource(DataFlow::Node source) {
...
}
predicate isSink(DataFlow::Node sink) {
...
}
predicate isBarrier(DataFlow::Node node) {
...
}
predicate isAdditionalFlowStep(DataFlow::Node n1, DataFlow::Node n2) {
...
}
}
module MyFlow = DataFlow::Global<MyFlowConfiguration>;isSource- 数据可能来自哪里isSink- 数据流向哪里isBarrier- 可选项,数据流被阻止的位置isAdditionalFlowStep- 可选项,添加额外的流程步骤
完成这样的定义后应用并调用定义的flow方法:
module MyFlow = DataFlow::Global<MyFlowConfiguration>
from DataFlow::Node source, DataFlow::Node sink
where MyFlow::flow(source, sink)
select source, "Data flow to $@.", sink, sink.toString()全局污点追踪
一样先写好配置,然后通过TaintTracking::Global实现即可。
在数据流库中包含一下预定义的源,这些可能在查找问题时十分有用;譬如RemoteFlowSource定义了由远程用户控制的数据流源。
在前面我们通过组合获取了所有的FastJSON的parse[XXX]方法调用,但是在实际分析中,只有用户可控的输入被传入了parse[XXX]才是有效的;因此我们使用全局污点追踪来完成这样的工作。
首先思路是:
- 来源是用户输入
- 流向了FastJSON的
parse[XXX]
于是模块可以这样定义:
import java
import semmle.code.java.dataflow.DataFlow
import semmle.code.java.dataflow.FlowSources
module FastJSONDerserializationVulConfig implements DataFlow::ConfigSig {
predicate isSource(DataFlow::Node src) {
src instanceof RemoteFlowSource
}
predicate isSink(DataFlow::Node sink) {
exists(MethodCall call |
call.getMethod().getName().regexpMatch("parse.*") and
call.getCallee().getDeclaringType().getQualifiedName() = "com.alibaba.fastjson.JSON" and
sink.asExpr() = call.getArgument(0)
)
}
}
module FastJSONDeserializationVulFlow = TaintTracking::Global<FastJSONDerserializationVulConfig>;
from DataFlow::Node source, DataFlow::Node sink
where FastJSONDeserializationVulFlow::flow(source, sink)
select source, sink.getLocation().getStartLine(), "FastJSON parse with user-controlled input may lead to deserialization vulnerability"样例 - 找出全局所有java.net.URL硬编码
很简单了,来源是字符串面量,流向了构造函数:
module URLHardCodeConfig implements DataFlow::ConfigSig {
predicate isSource(DataFlow::Node src) {
src.asExpr() instanceof StringLiteral
}
predicate isSink(DataFlow::Node sink) {
exists(Constructor c, Call call |
c.getDeclaringType().getQualifiedName() = "java.net.URL" and
call.getCallee() = c and
sink.asExpr() = call.getArgument(0)
)
}
}
module URLHardCodeFlow = DataFlow::Global<URLHardCodeConfig>;
from DataFlow::Node source, DataFlow::Node sink
where URLHardCodeFlow::flow(source, sink)
select source, sink, "Hard-coded URL used in URL constructor"官方的答案更加简洁一点:
import java
import semmle.code.java.dataflow.DataFlow
module LiteralToURLConfig implements DataFlow::ConfigSig {
predicate isSource(DataFlow::Node source) {
source.asExpr() instanceof StringLiteral
}
predicate isSink(DataFlow::Node sink) {
exists(Call call |
sink.asExpr() = call.getArgument(0) and
call.getCallee().(Constructor).getDeclaringType().hasQualifiedName("java.net", "URL")
)
}
}
module LiteralToURLFlow = DataFlow::Global<LiteralToURLConfig>;
from DataFlow::Node src, DataFlow::Node sink
where LiteralToURLFlow::flow(src, sink)
select src, "This string constructs a URL $@.", sink, "here"当然我的查询也没有问题,不过多做一些笛卡尔积,使用call.getCallee().(Construcotr)来确保调用为构造方法是更好的选择。
流源定义
在上面的FastJSON污点追踪的例子里,使用了RemoteFlowSource,库中的源有时不一定符合我们的要求,所以需要自己定义;流源的定义非常简单,只需要在构造器中指定条件即可:
class DemoSource {
DemoSource() {
...
}
}假设我们需要获取System.getenv的源,那么定义非常简单:
import java
class GetenvSource extends MethodCall {
GetenvSource() {
exists(Method m | m = this.getMethod() |
m.hasName("getenv") and
m.getDeclaringType() instanceof TypeSystem
)
}
}TypeSystem,就是java.lang.System类。
这里extends MethodCall是为了方便获取方法;注意这里的source也是一个MethodCall类型。
样例 - 找出全局所有通过System.getenv定义的URL对象
直接引入上面的即可,然后判断流入构造函数:
import java
import semmle.code.java.dataflow.DataFlow
class GetenvSource extends DataFlow::ExprNode {
GetenvSource() {
exists(Method m | m = this.asExpr().(MethodCall).getMethod() |
m.hasName("getenv") and
m.getDeclaringType() instanceof TypeSystem
)
}
}
module GetenvToURLConfig implements DataFlow::ConfigSig {
predicate isSource(DataFlow::Node source) {
source instanceof GetenvSource
}
predicate isSink(DataFlow::Node sink) {
exists(Call call |
sink.asExpr() = call.getArgument(0) and
call.getCallee().(Constructor).getDeclaringType().hasQualifiedName("java.net", "URL")
)
}
}
module GetenvToURLFlow = DataFlow::Global<GetenvToURLConfig>;
from DataFlow::Node src, DataFlow::Node sink
where GetenvToURLFlow::flow(src, sink)
select src, "This environment variable constructs a URL $@.", sink, "here"路径查询
通过数据流分析能帮我们找到source和sink,但是不能知道是怎么传播的;通过路径查询则可以做到这一点
路径查询实际上在数据流的基础上进行的;因此必须先学会构建数据流才能进行下一步。
模板
构建路径查询可以使用以下的模板:
/**
* ...
* @kind path-problem
* ...
*/
import <language>
// For some languages (Java/C++/Python/Swift) you need to explicitly import the data flow library, such as
// import semmle.code.java.dataflow.DataFlow or import codeql.swift.dataflow.DataFlow
...
module Flow = DataFlow::Global<MyConfiguration>;
import Flow::PathGraph
from Flow::PathNode source, Flow::PathNode sink
where Flow::flowPath(source, sink)
select sink.getNode(), source, sink, "<message>"元数据声明
注意元数据@kind path-problem是必选项,没有这个选项则不能构建路径查询。
路径
在Flow::PathGraph中已经包含了edges,当然也可以自己定义:
query predicate edges(PathNode a, PathNode b) {
/* Logical conditions which hold if `(a,b)` is an edge in the data flow graph */
}Soucre和Sink
这个查询和全局数据流很像,只需要将from从DataFlow::Node改为Flow::PathNode,注意这里的Flow并非固定的,而是module Flow = ...这里的Flow;然后将DataFlow::flow改为Flow::flowPath即可。
select约定
注意路径查询的select应该为四列:
select element, source, sink, stringelement和string分别表示警报和劲爆消息;source和sink则是路径图上的节点;关联到此结果的路径可以在拓展中查看。
性能优化
避免超大笛卡尔积
和SQL类似的,CodeQL最可能出现的性能瓶颈也是在笛卡尔积上出现。
看这个例子:
predicate mayAccess(Method m, Field f) {
f.getAnAccess().getEnclosingCallable() = m
or
not exists(m.getBody())
}这里假定一个无方法体的方法可能访问任意字段,因此也将其进行筛选出来;不过这里造成了非常严重的问题,通过or连接的逻辑表达式,在第二个逻辑表达式中不存在和f关联的表达,这意味着字段f将和所有的满足该条件的m做笛卡尔积,形成超大结果集。
避免定义陷阱
class Foo extends Class {
...
// BAD! Does not use ‘this’
Method getToString() {
result.getName() = "ToString"
}
...
}参考这个定义,getToString表面上看起来似乎是获取当前类的ToString方法,但是实际上获取的是所有ToString方法。
之所以会出现这样的原因,是因为这里有两个隐式参数,一个为this,一个为result,这里只对result进行了限定,而没有对this进行限定,所以每个this都将和ToString方法作笛卡尔积。
应该写为:
class Foo extends Class {
...
Method getToString() {
result.getName() = "ToString" and
this.getAMehotd() = result
}
...
}为了更好的理解,我们以提取FJ的解析方法为例,如果是这样的查询:
import java
class FastJSON extends Class {
FastJSON() {
this.hasQualifiedName("com.alibaba.fastjson", "JSON")
}
Method getParseMethod() {
result.getName().regexpMatch("parse.*")
}
}
from FastJSON fjc, Method m
where m = fjc.getParseMethod()
select m, m.getSignature(), m.getDeclaringType()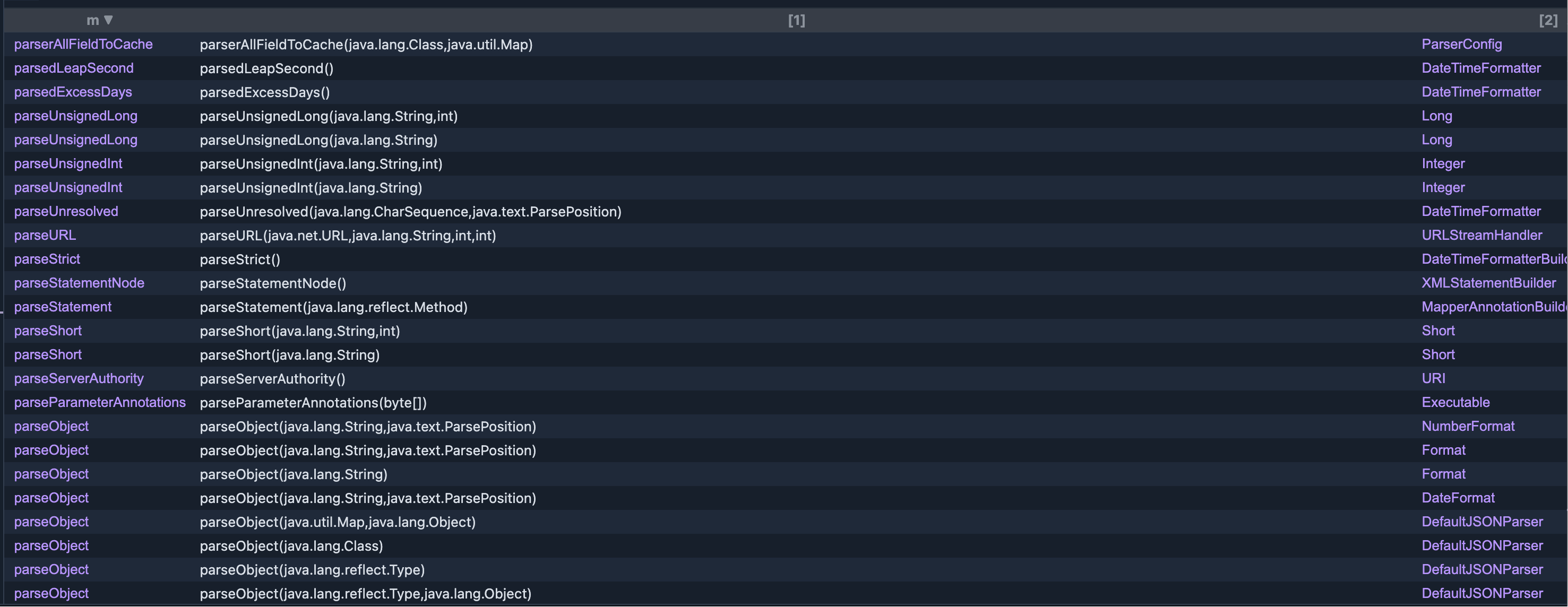
从结果集中我们可以看出,提取的确实是所有的parse方法,不是JSON类的也被提取出来了,这就是因为this没有进行限定;接下来我们限定一让这个方法为this的方法,理论上就可以了:
import java
class FastJSON extends Class {
FastJSON() {
this.hasQualifiedName("com.alibaba.fastjson", "JSON")
}
Method getParseMethod() {
result.getName().regexpMatch("parse.*") and
result = this.getAMethod()
}
}
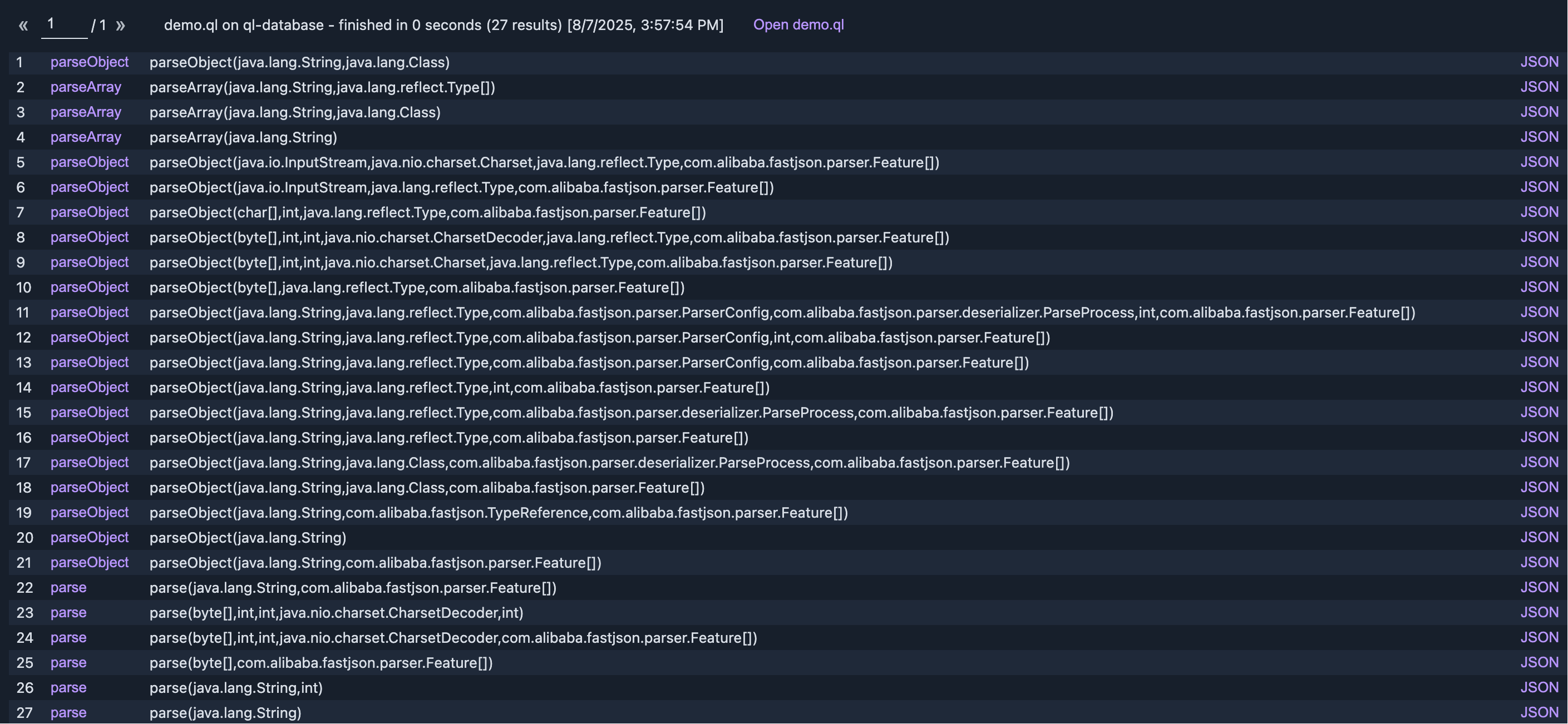
from FastJSON fjc, Method m
where m = fjc.getParseMethod()
select m, m.getSignature(), m.getDeclaringType()如图:
使用最准确的类型变量
如果不熟悉库中提供的类型,那么可以通过Expr.getAQlClass来获取;例如:
import java
from Expr e, Callable c
where
c.getDeclaringType().hasQualifiedName("my.namespace.name", "MyClass")
and c.getName() = "c"
and e.getEnclosingCallable() = c
select e, e.getAQlClass()注意这个不能在最终的查询中使用,它非常消耗性能。
避免复杂递归
和常规编程类似,必须保证递归的出口存在,否则就会导致异常。
谓词折叠
这实际上还是避免超大笛卡尔积产生的一种方式,看下面的查询:
predicate similar(Element e1, Element e2) {
e1.getName() = e2.getName() and
e1.getFile() = e2.getFile() and
e1.getLocation().getStartLine() = e2.getLocation().getStartLine()
}对于查询来说,这个谓词是性能极低的,假设有元素1000个,那么至少要做1000*1000次比对。类比SQL来解释这个问题,上面的查询对于SQL来说可以这么写
SELECT e1.id, e2.id FROM elements e1, elements e2
WHERE e1.getName() = e2.getName() AND e1.getFile() = e2.getFile() AND e1.getStartLine() = e2.getStartLine() AND e1.id != e2.id;这里为什么低效呢?如下:
FOR each row r1 in elements (1000 rows)
FOR each row r2 in elements (1000 rows) -- 1,000,000 次循环
compute r1.getName(), r1.getFile(), r1.getStartLine() -- 重复计算
compute r2.getName(), r2.getFile(), r2.getStartLine() -- 重复计算
if conditions match: output (r1, r2)所以问题出现在了多次的重复计算上面;也就是CodeQL的谓词被多次调用了,但是实际上这是不需要的,在程序中我们一般通过缓存来避免某些耗时操作重复调用;在这里也是一样,Element的集合是确定的,我们可以先用1000次循环将所有的值计算后再进行组合判断。
这就是谓词折叠的核心思想,先物化谓词结果,再进行比对。
上面的优化就可以写为:
predicate locInfo(Element e, string name, File f, int startLine) {
name = e.getName() and
f = e.getFile() and
startLine = e.getLocation().getStartLine()
}
predicate sameLoc(Element e1, Element e2) {
exists(string name, File f, int startLine |
locInfo(e1, name, f, startLine) and
locInfo(e2, name, f, startLine)
)
}这实际上和SQL中的谓词下推优化是一样的,尽可能早的确定数据,以减少笛卡尔积的大小。
或许理解起来还是稍加费力,不过记住这个原则进行优化即可:
当多个线性操作直接作用于多个元素时,应将其元素操作移动至单一谓词进行。
例如:
predicate test(Element e1, Element e2) {
e1.getA() = e2.getA() and
e1.getB() = e2.getB() and
...
}则应改写为:
predicate tester(Element e, A a, B b...) {
e.getA() = a and
e.getB() = b and
...
}
predicate test(Element e1, Element e2) {
exists(A a, B b... |
tester(e1, a, b...) and
tester(e2, a, b...)
)
}
部分流
这个章节是给数据流补充的,如果在数据流中没有获取到预期的结果,那么可以使用部分流来调试数据流。
检查source和sink
如果source和sink是空的,那么不可能存在任何流,因此第一时间应该先排查source和sink是否存在,在VSCode中,安装插件后,可以对语句进行选择右键快速执行筛选出source和sink;查看结果中是否包含自己预想的source和sink即可。
fieldFlowBranchLimit
在数据流的配置项中,存在这样的一个参数用于控制字段流的分支数限制,但这个数小了时,可能漏掉一些结果,如果大了,也可能导致分析更复杂、更慢。
在配置项中可以修改其配置:
int fieldFlowBranchLimit() { result = 5000 }注意他应该在流的配置中,也就是module xxx implement DataFlow::ConfigSig的里面。
部分流
如果检查过source和sink,并且也调整过fieldFlowBranchLimit的值,但是还是没找到流,那么可以使用部分流来进行调试。
注意,不要将sink设置为any来尝试找出问题,这性能非常差,并且由于剪枝的存在,你可能根本无法发现问题。
为了调试流的走向,通过部分流,忽略sink,从我们的source走下去,检查为什么流没走通,谓词为predicate partialFlow(PartialPathNode source, PartialPathNode node, int dist)。
以一个具体的例子来看,使用下面的查询能不能找到RCE:
/**
* @name RCE Vulnerability
* @description Finds potential RCE vulnerabilities.
* @id java/examples/rce-vul
* @kind path-problem
* @problem.severity error
* @tags security
*/
import java
import semmle.code.java.dataflow.DataFlow
import semmle.code.java.dataflow.FlowSources
module RCEVulConfig implements DataFlow::ConfigSig {
predicate isSource(DataFlow::Node src) {
src instanceof RemoteFlowSource
}
predicate isSink(DataFlow::Node sink) {
exists(MethodCall call |
call.getMethod().getName() = "start" and
call.getCallee().getDeclaringType().getQualifiedName() = "java.lang.ProcessBuilder" and
sink.asExpr() = call.getQualifier()
)
}
}
module RCEVulFlow = TaintTracking::Global<RCEVulConfig>;
import RCEVulFlow::PathGraph
from RCEVulFlow::PathNode source, RCEVulFlow::PathNode sink
where RCEVulFlow::flowPath(source, sink)
select sink.getNode(), source, sink, "User-controlled input to ProcessBuilder.start() may lead to RCE"然而这个查询在存在RCE的代码中没有返回结果。
安装步骤,先检查source和sink,RemoteFlowSource自然是没有问题的,那么sink呢?

我们发现sink也没有问题,确实是预想的sink;代码也非常简单,不可能由于分支数限制导致的无法找到。
我们编写部分流来看看为什么:
/**
* @name RCE Vulnerability
* @description Finds potential RCE vulnerabilities.
* @id java/examples/rce-vul
* @kind path-problem
* @problem.severity error
* @tags security
*/
import java
import semmle.code.java.dataflow.DataFlow
import semmle.code.java.dataflow.FlowSources
module RCEVulConfig implements DataFlow::ConfigSig {
predicate isSource(DataFlow::Node src) {
src instanceof RemoteFlowSource and
src.getType() instanceof TypeString and
exists(Parameter p |
p.getName() = "command" and
src.asParameter() = p and
p.getCallable().getName() = "One"
)
}
predicate isSink(DataFlow::Node sink) {
exists(MethodCall call |
call.getMethod().getName() = "start" and
call.getCallee().getDeclaringType().getQualifiedName() = "java.lang.ProcessBuilder" and
sink.asExpr() = call.getQualifier()
)
}
}
int explorationLimit() { result = 20 }
module RCEVulFlow = TaintTracking::Global<RCEVulConfig>;
module RCEVulPartialFlow = RCEVulFlow::FlowExplorationFwd<explorationLimit/0>;
import RCEVulPartialFlow::PartialPathGraph
from RCEVulPartialFlow::PartialPathNode source, RCEVulPartialFlow::PartialPathNode node
where RCEVulPartialFlow::partialFlow(source, node, _)
select node.getNode(), source, node, "Partial flow from " + source.getNode().toString() + " to " + node.getNode().toString()
注意这里部分流的使用,然后得到了输出:
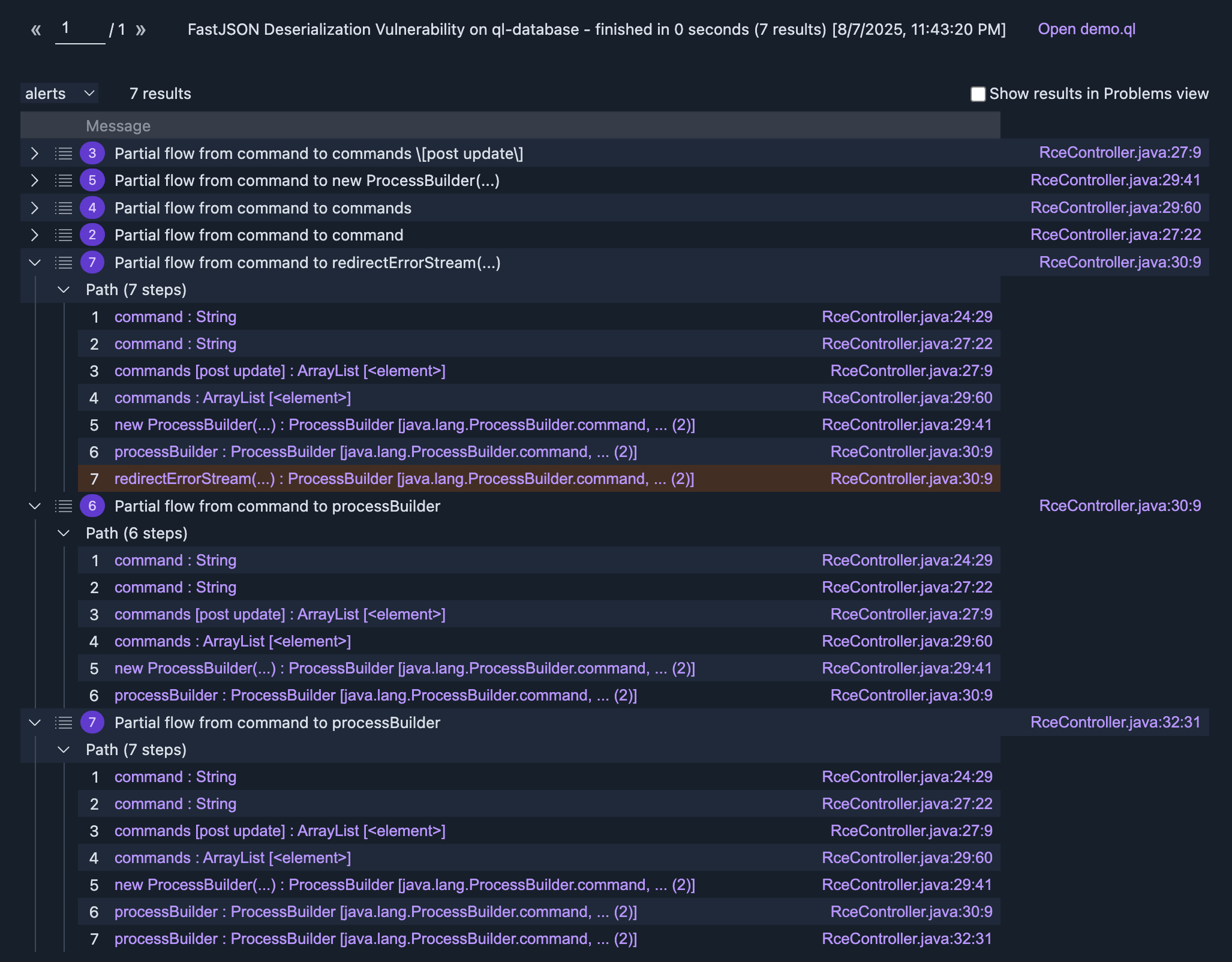
然后就是每个流的筛查了,我们最终的sink实际上是processBuilder,因此这里我们就看最后两个即可;在这里我们可以看到,流源流入了processBuilder的command等字段,然后流就断了;这是因为我们的sink定义要求为processBuilder实例且调用start方法,那么为什么会断呢?很显然,这里由于流到了processBuilder的command等字段,但是没有认定processBuilder是污点,因此在最后识别调用start时断掉了。
所以这里我们需要手动将其连接起来,通过上面说过的isAdditionalFlowStep,我们将流从构造方法连接起来:
/**
* @name RCE Vulnerability
* @description Finds potential RCE vulnerabilities.
* @id java/examples/rce-vul
* @kind path-problem
* @problem.severity error
* @tags security
*/
import java
import semmle.code.java.dataflow.DataFlow
import semmle.code.java.dataflow.FlowSources
module RCEVulConfig implements DataFlow::ConfigSig {
predicate isSource(DataFlow::Node src) {
src instanceof RemoteFlowSource and
src.getType() instanceof TypeString and
exists(Parameter p |
p.getName() = "command" and
src.asParameter() = p and
p.getCallable().getName() = "One"
)
}
predicate isSink(DataFlow::Node sink) {
exists(MethodCall call |
call.getMethod().getName() = "start" and
call.getCallee().getDeclaringType().getQualifiedName() = "java.lang.ProcessBuilder" and
sink.asExpr() = call.getQualifier()
)
}
predicate isAdditionalFlowStep(DataFlow::Node f, DataFlow::Node t) {
exists(ConstructorCall cc |
cc.getConstructor().getDeclaringType().getQualifiedName() = "java.lang.ProcessBuilder" and
t.asExpr() = cc and
exists(int i |
i < cc.getNumArgument() and
f.asExpr() = cc.getArgument(i)
)
)
}
}
int explorationLimit() { result = 20 }
module RCEVulFlow = TaintTracking::Global<RCEVulConfig>;
module RCEVulPartialFlow = RCEVulFlow::FlowExplorationFwd<explorationLimit/0>;
import RCEVulPartialFlow::PartialPathGraph
from RCEVulPartialFlow::PartialPathNode source, RCEVulPartialFlow::PartialPathNode node
where RCEVulPartialFlow::partialFlow(source, node, _)
select node.getNode(), source, node, "Partial flow from " + source.getNode() + " to " + node.getNode().toString()此时输出:
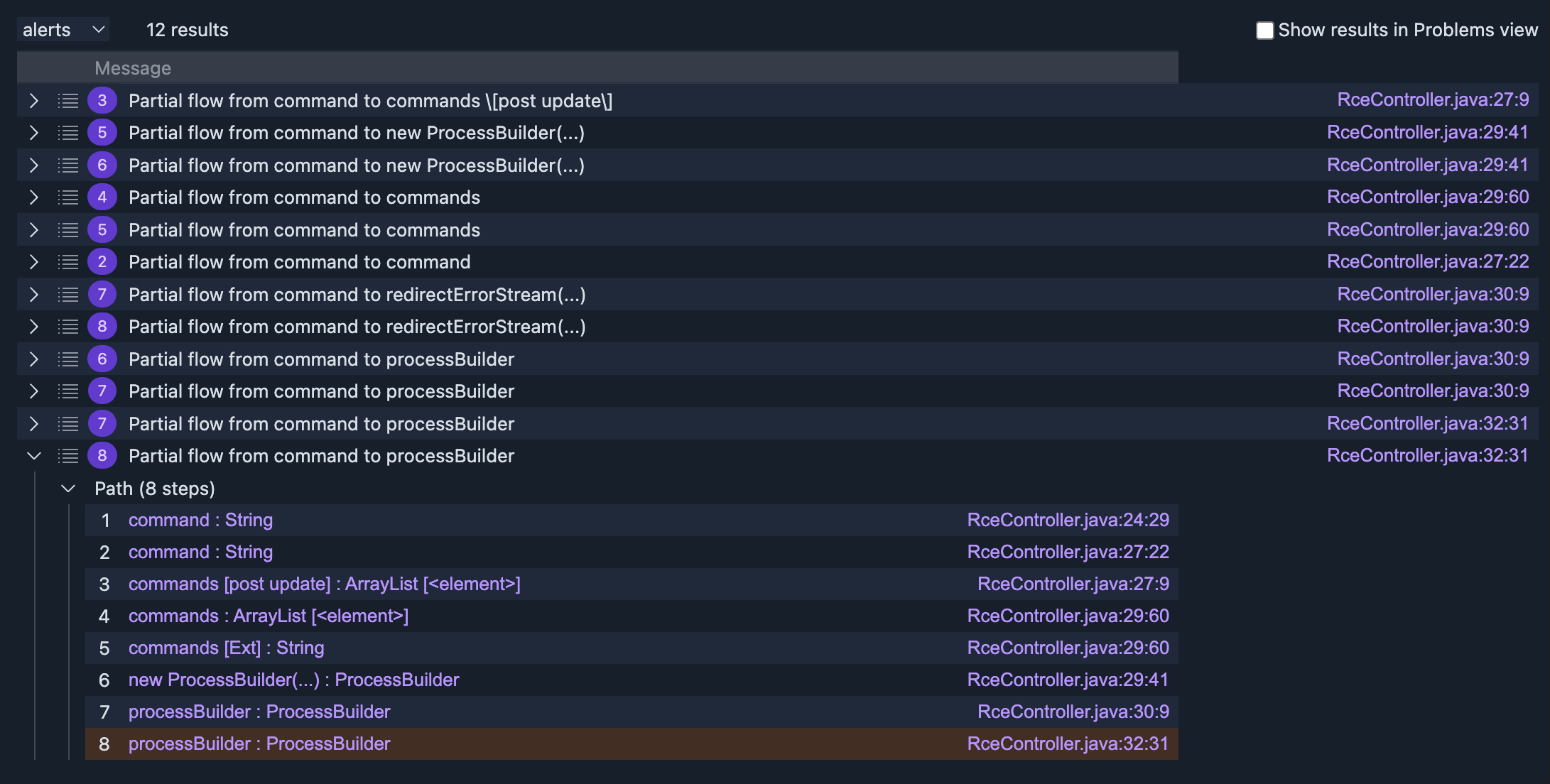
那么在这里就可以看到了,这里new ProcessBuilder后,将ProcessBuidler视为了污点,进而到RceController:32:31成功识别出。
给出完整代码:
/**
* @name RCE Vulnerability
* @description Finds potential RCE vulnerabilities.
* @id java/examples/rce-vul
* @kind path-problem
* @problem.severity error
* @tags security
*/
import java
import semmle.code.java.dataflow.DataFlow
import semmle.code.java.dataflow.FlowSources
module RCEVulConfig implements DataFlow::ConfigSig {
predicate isSource(DataFlow::Node src) {
src instanceof RemoteFlowSource and
src.getType() instanceof TypeString and
exists(Parameter p |
p.getName() = "command" and
src.asParameter() = p and
p.getCallable().getName() = "One"
)
}
predicate isSink(DataFlow::Node sink) {
exists(MethodCall call |
call.getMethod().getName() = "start" and
call.getCallee().getDeclaringType().getQualifiedName() = "java.lang.ProcessBuilder" and
sink.asExpr() = call.getQualifier()
)
}
predicate isAdditionalFlowStep(DataFlow::Node src, DataFlow::Node dst) {
exists(ConstructorCall cc |
cc.getConstructor().getDeclaringType().getQualifiedName() = "java.lang.ProcessBuilder" and
dst.asExpr() = cc and
exists(int i |
i < cc.getNumArgument() and
src.asExpr() = cc.getArgument(i)
)
)
}
}
module RCEVulFlow = TaintTracking::Global<RCEVulConfig>;
import RCEVulFlow::PathGraph
from RCEVulFlow::PathNode source, RCEVulFlow::PathNode sink
where RCEVulFlow::flowPath(source, sink)
select sink.getNode(), source, sink, "User-controlled input to ProcessBuilder.start() may lead to RCE"快速分析
如果希望快速分析一个流,只需要在查询中添加一个谓语然后使用快速执行即可:
predicate adhocPartialFlow(Callable c, MyPartialFlow::PartialPathNode n, DataFlow::Node src, int dist) {
exists(MyPartialFlow::PartialPathNode source |
MyPartialFlow::partialFlow(source, n, dist) and
src = source.getNode() and
c = n.getNode().getEnclosingCallable()
)
}注意这里尽可能去优化自己的输出,譬如A->B->C->D->E断了,那么可以先查A->B->C是否断了,再查C->D->E。